The language model (LM) is an essential building block of current AI systems dealing with natural language, and has proven to be useful in tasks as diverse as sentiment analysis, text generation, translations, and summarizing. These LMs are typically based on neural networks and trained on vast amounts of training data, which make these so effective, but this doesn’t come without any problems.
LMs have also been shown to learn undesirable biases towards certain social groups, which may unfairly influence the decisions, recommendations or texts that AI systems building on those LMs generate. Research on detecting such biases is crucial, but as new LMs are continuously developed, it is equally important to study how LMs come to be biased in the first place, and what role the training data, architecture, and downstream application play at various phases in the life-cycle of an NLP model.
In this blog post, we outline our work towards a better understanding of the origins of bias in LMs by investigating the learning dynamics of an LSTM-based language model trained on an English Wikipedia corpus.
Gender bias for occupations in LMs
In our research, we studied a relatively small LM based on the LSTM architecture and only consider one of the most studied types of bias in language models: gender bias. Because of this constrained focus, we were able to leverage previous work on measuring gender bias and get a detailed view of how it is learnt from the start of training, which wouldn’t be feasible with a very large pre-trained LM.
In the image below you see a typical language modelling pipeline. As you can see there are multiple stages where the gender bias of a word can be measured: (I) in the (training) dataset of the model, (II) in the input embeddings (IE), which comprise the first layer of the LM, or (III) at the end of the pipeline in a downstream task that makes use of the contextual embeddings of the model.
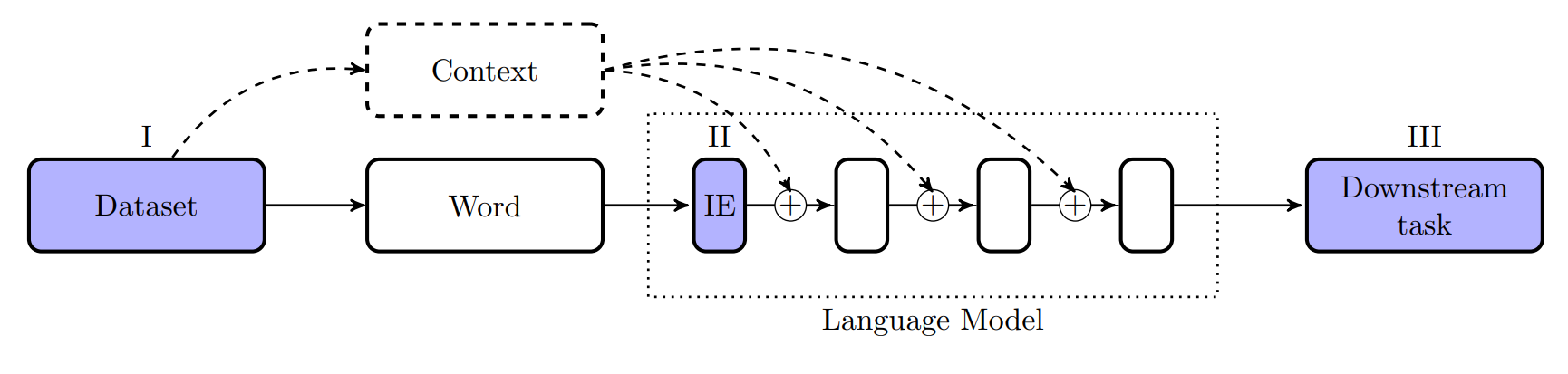
At each of these stages, we measure the gender bias of the LM. Defining (undesirable) bias is a complicated matter, however, and there are many definitions and frameworks discussed in the literature. In our work, we used gender-neutrality as the norm, and define bias as any significant deviation from a 50-50% distribution in preferences, probabilities or similarities.
The evolution of gender representation in the input embeddings
Before we studied the gender bias for occupation terms, we first focused on the question: How does the LM learn a representation of gender during training, and how is that representation encoded in the input embeddings? To answer this question, we trained several linear classifiers to predict the gender of 82 gendered word pairs (e.g. “he”-“she”, “son”-“daughter”, etc.).
How good is this classifier if we give it all the axes of the input embedding space? And what if we only give it the single best one (which we call the gender unit)? Interestingly, we find that after around 2 epochs of training, only using the gender unit as input outperforms using all the other axes of the input embedding space!
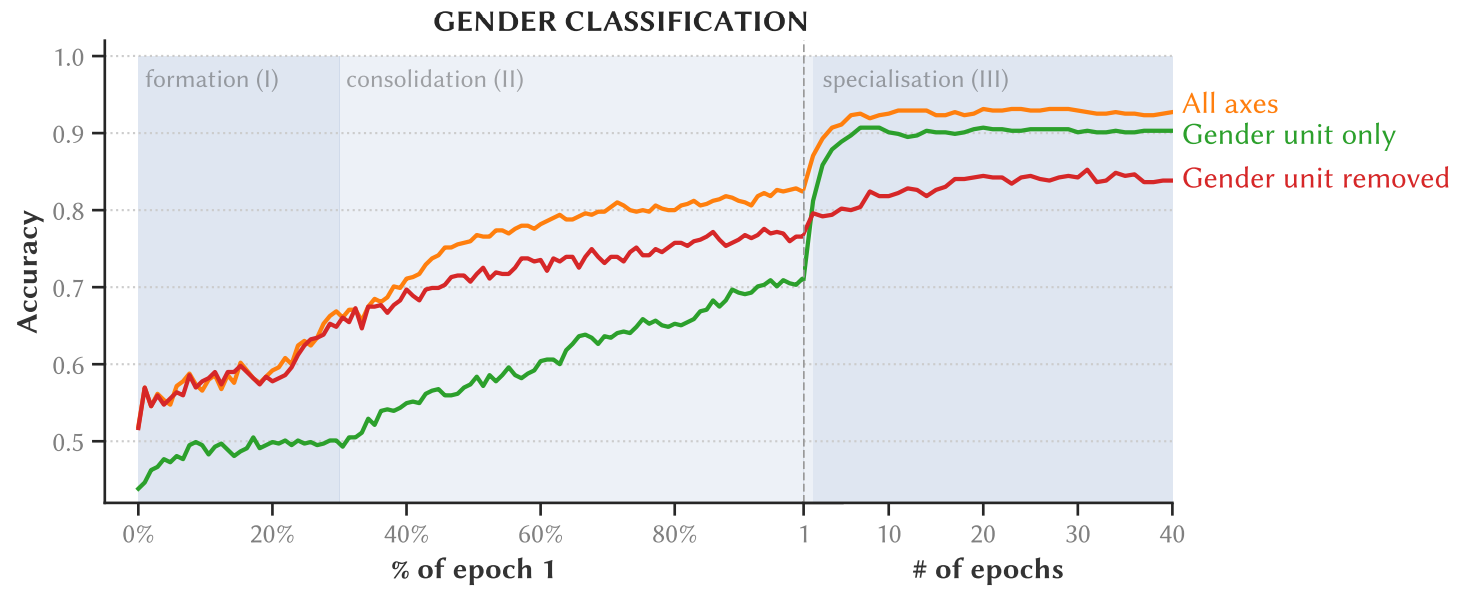
Another interesting finding, is that the dominant gender unit seems to be specialized for marking female words in particular, while information on the male words is distributed over the rest of the input embedding space.

The evolution of gender bias
Using a linear decision boundary for studying how gender is represented in an embedding space is actually very similar to one class of (gender) bias measures: those based on finding a linear gender subspace.
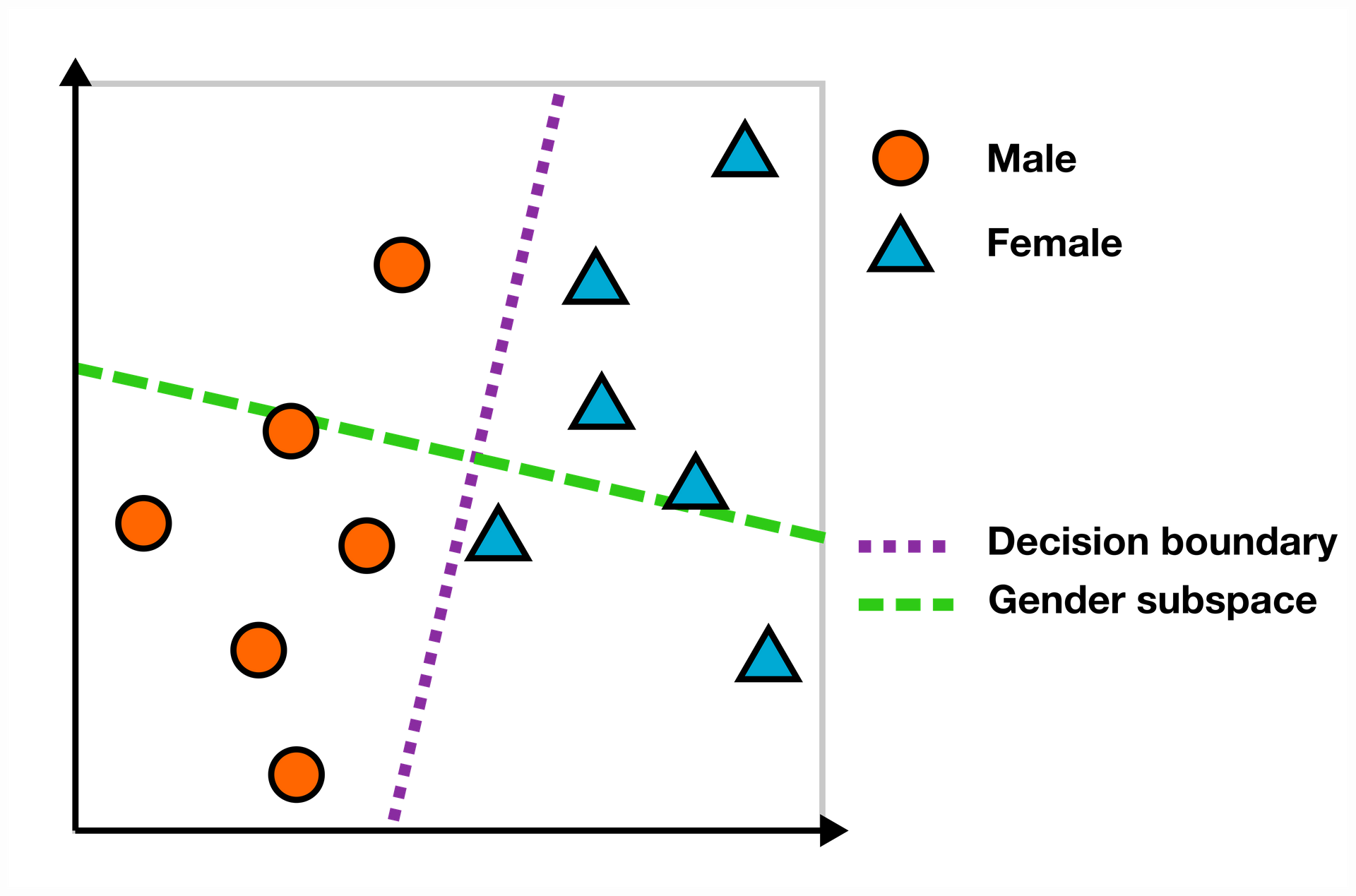
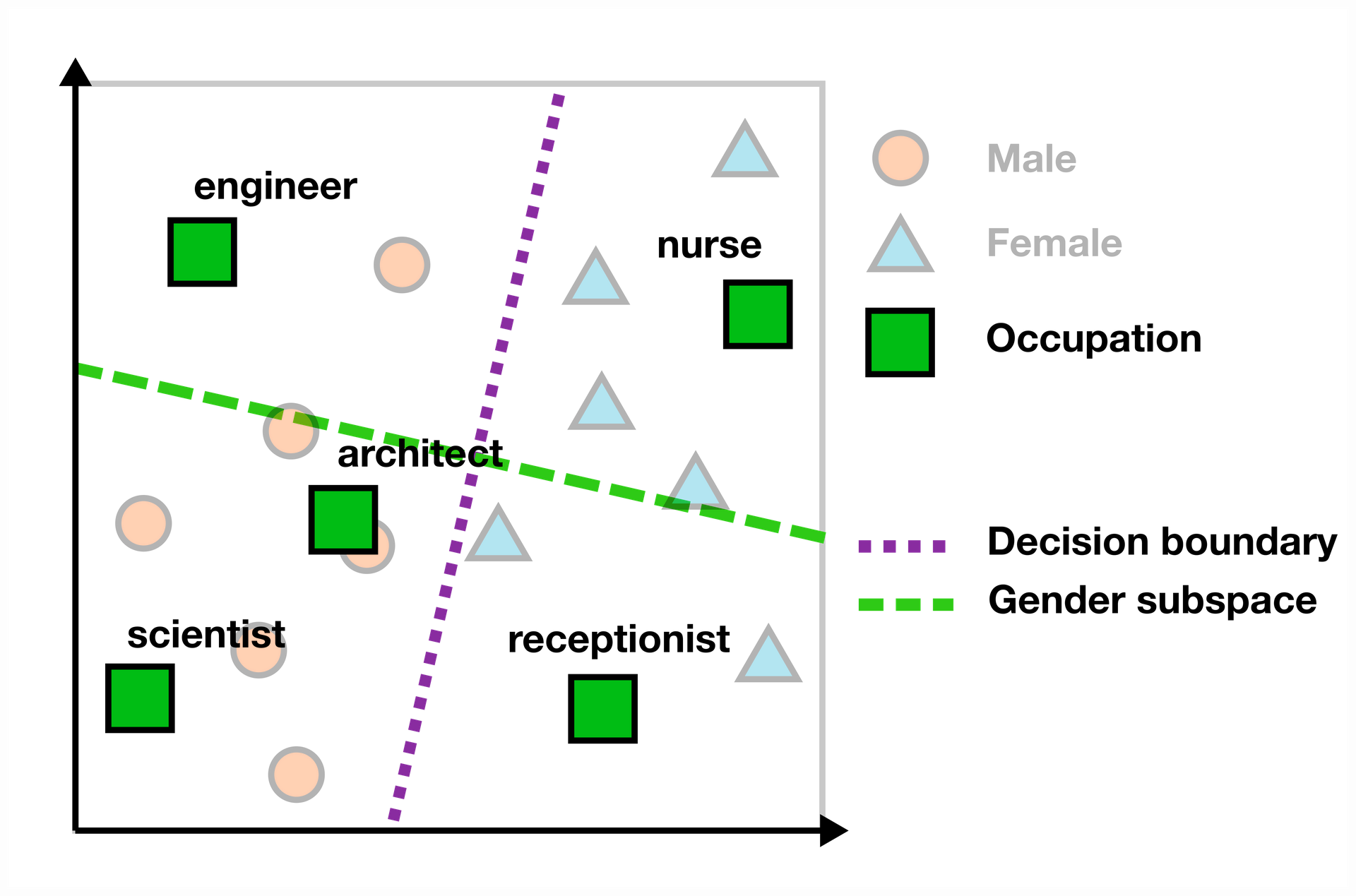
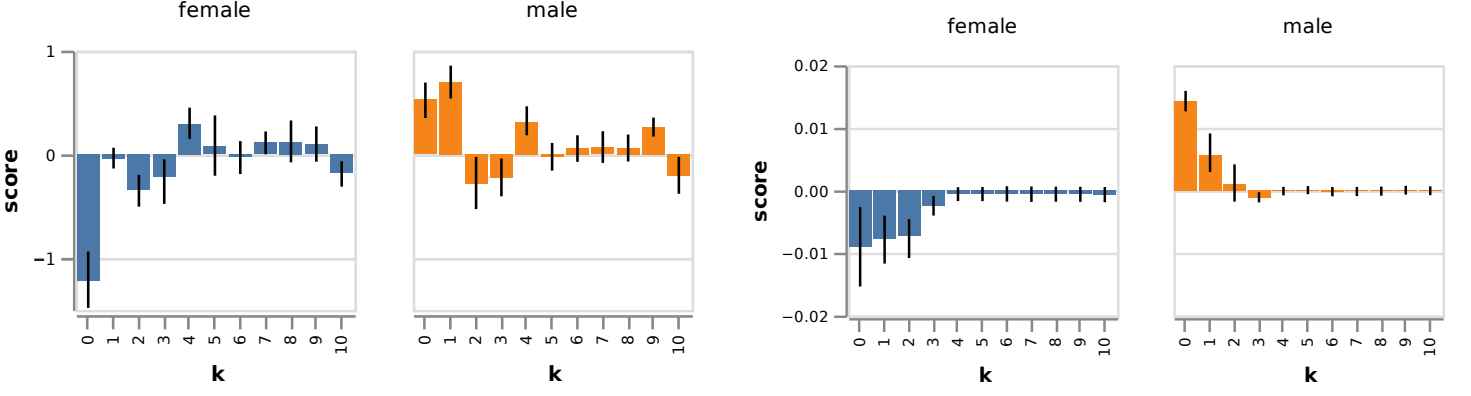
For finding the bias score of a word in the embedding space, you can look at the scalar projection on the gender subspace. In the example below, words like “engineer” and “scientist” are on the “male” side of the subspace, while “nurse” and “receptionist” have a female bias.
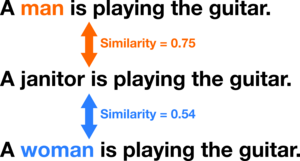
We also measure the gender bias in a downstream task, in particular the semantic textual similarity task for bias (STS-B). In this task, the LM is used for estimating the similarity of three sentences, containing either the word “man”, “woman”, or an occupation term.
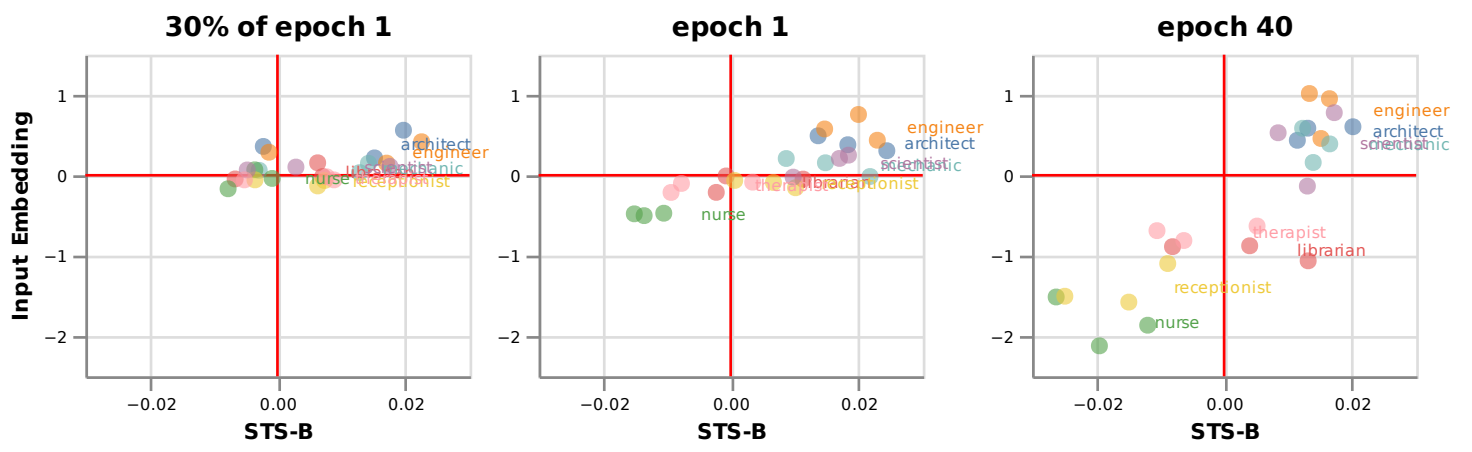
We find a striking gender bias in both representations (which even correlates with the percentage of male versus female workers in official US Labour Statistics).
Diagnostic intervention: changing downstream bias by changing embeddings
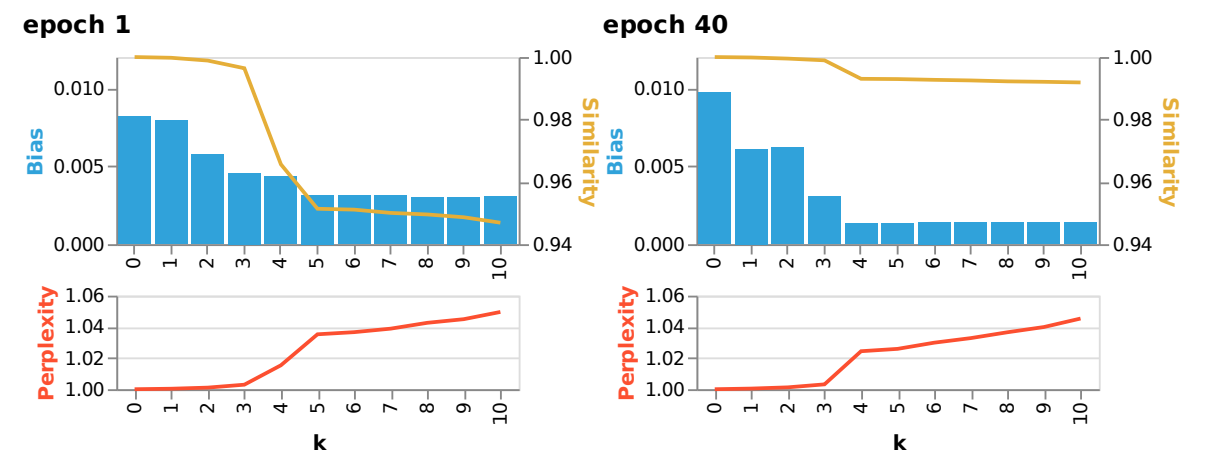
We also did a diagnostic intervention: does debiasing the input embeddings result in a measurable effect on the bias measured downstream.
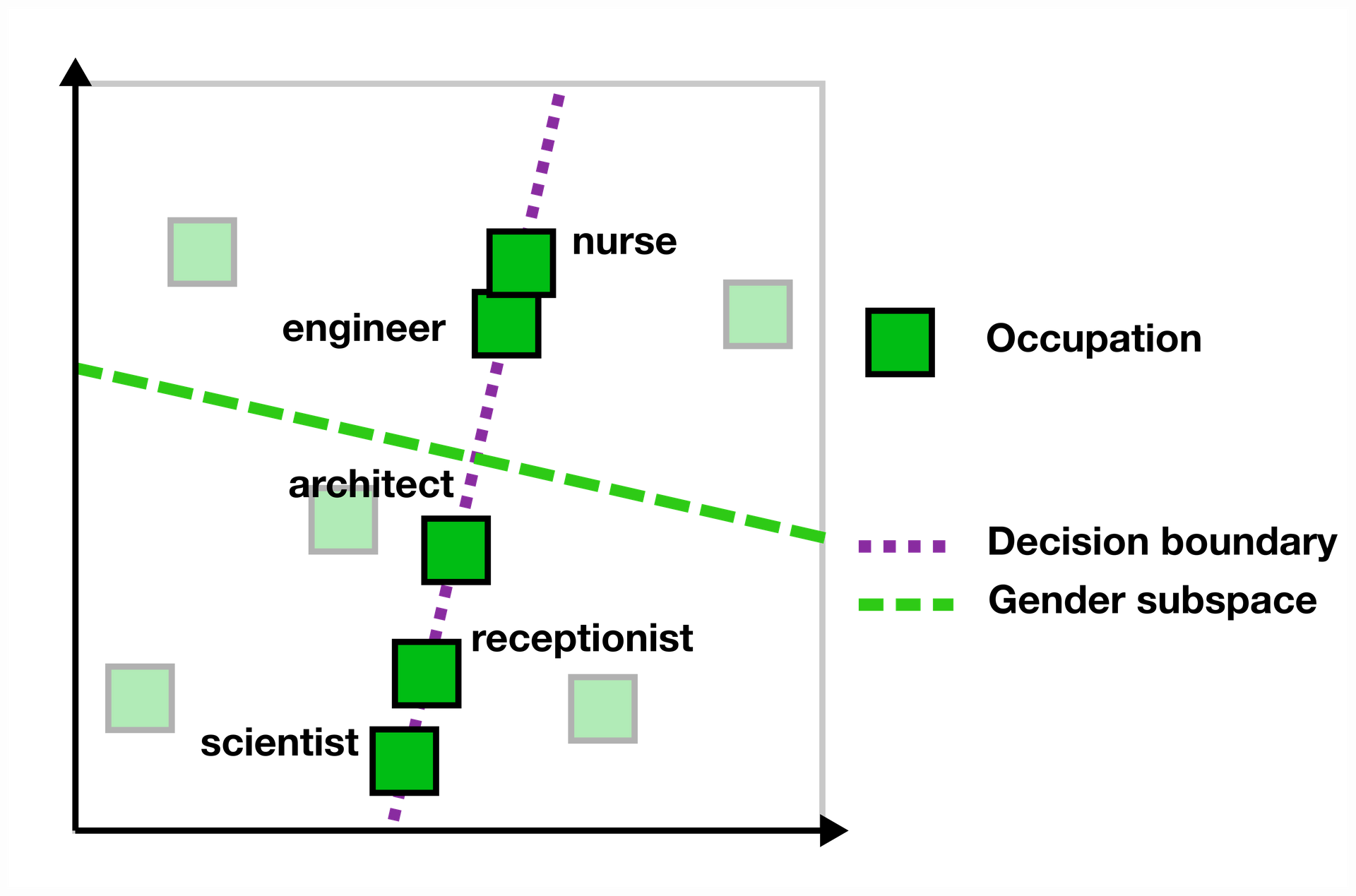
We find that debiasing is much more effective at the end of the training, and that doing this only three times reduces the bias without many side-effects.
Conclusion
- We identify different phases in the learning dynamics of gender (bias): in how locally it is represented and the different dataset features that can explain these.
- We have seen that the concept of gender is encoded increasingly locally in the input embeddings during training, and that the dominant gender unit specializes in feminine word information.
- The bias measured in the input embeddings are fairly predictive of the bias measured downstream in a simple task. We even found that debiasing the input embeddings is effective in reducing the downstream bias, indicating some causal relationship.
- We observed a striking gender asymmetry in our results, underscoring the importance of understanding how the (gender) bias is represented in the internal state of the LM, as naive debiasing may introduce new biases.