📄 Undesirable Biases in NLP: Addressing Challenges of Measurement
This post is about our paper "Undesirable Biases in NLP: Addressing Challenges of Measurement", published in JAIR.
Developing tools for measuring & mitigating bias is challenging: LM bias is a complex sociocultural phenomenon and we have no access to a ground truth. We voice our concerns about current bias evaluation practices, and discuss how we can ensure the quality of bias measures despite these challenges.
Operationalizations of Bias
Borrowing from psychometrics (a field specialized in the measurement of concepts that are not directly observable), we argue that it is useful to decouple the "construct" (what we want to know about but cannot observe directly) from its "operationalization" (the imperfect proxy).
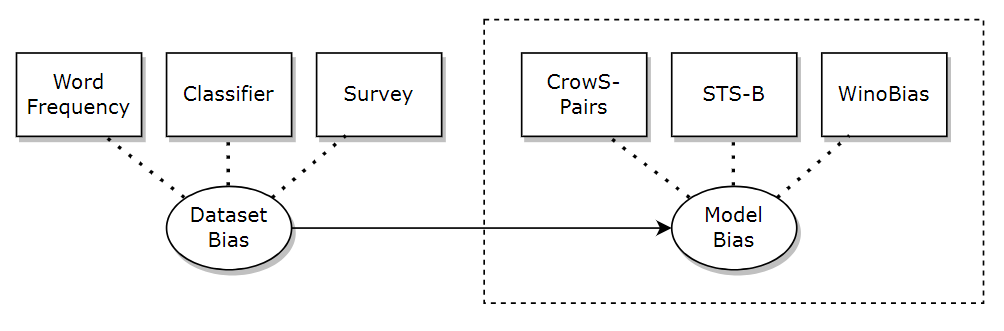
It's important to understand the difference! For instance, a twice-as-high bias score (operationalization) does not necessarily mean that the model is twice as biased (construct). Making this distinction allows us to be more explicit about our assumptions and conceptualizations.
We discuss two important concepts that say something about the quality of bias measures: reliability and construct validity. For both, we discuss strategies for how to assess these in the NLP setting.
Reliability
How much precision can we get when applying the bias measure? How resilient is it to random measurement error? Naturally, we prefer measurement tools with a higher reliability! In our paper we discuss four forms of reliability we think can be applied easily to the NLP context.
| Reliability type | Consistency across | Example application |
|---|---|---|
| Inter-rater | (Human) annotators | Annotating potential test items |
| Internal consistency | Test items of a measure | Templates |
| Parallel-form | Alternative versions of a measure | Bias benchmarks & prompts |
| Seed-based test-retest | Random seeds | Model retraining |
| Corpus-based test-retest | Training data sets | Model retraining |
| Time-based test-retest | Time | Training steps & temporal data |
For instance, parallel-form reliability tests if different—but designed to be equivalent—versions of a measure are consistent. E.g., how consistent are different prompt formulations for evaluating the LM responses on the same bias dataset? Are LMs sensitive to minor changes to how the questions are phrased?
Relatedly, Leshem Choshen and his co-authors comes with a compelling argument: not the size of a benchmark, but its reliability matters! We waste valuable resources when computing results for test items that do not contribute to the overall reliability of the dataset.
Construct Validity
How sure are we that we measure what we actually want to measure (the construct)? Critical work by e.g., Gonen & Goldberg, Blodgett et al., Orgad & Belinkov shows many flaws that could hurt the validity. How do we design bias measures that actually measure what we want?
| Validity type | Focus | Example |
|---|---|---|
| Convergent: Do measurements from this instrument relate to measures that they should relate to? | related measure or construct | downstream harm |
| Divergent: Do measurements from this instrument not relate (or only relate weakly) to measures that they should not relate (or only relate weakly) to? | confounding construct | general model capability |
| Content: Are all relevant sub-components of the construct represented sufficiently by measures from this instrument? Is none of the instrument's materials construct( subcomponent)-irrelevant? | relevant subcomponents of the construct | different forms of gender bias |
Ideally, one would test the validity by comparing one’s bias results with a gold standard (criterion validity). Unfortunately, we do not have access to this for something like model bias. However, there exist alternative (weaker) strategies for validating bias benchmarks!
Convergent and Divergent Validity
An obvious approach is to test the convergent validity: How well do our bias scores relate to other bias measures? And—more importantly—to the downstream harms of LMs? (Sometimes called predictive validity) See, for example, the work by Delobelle et al., Goldfarb-Tarrant et al., and others.
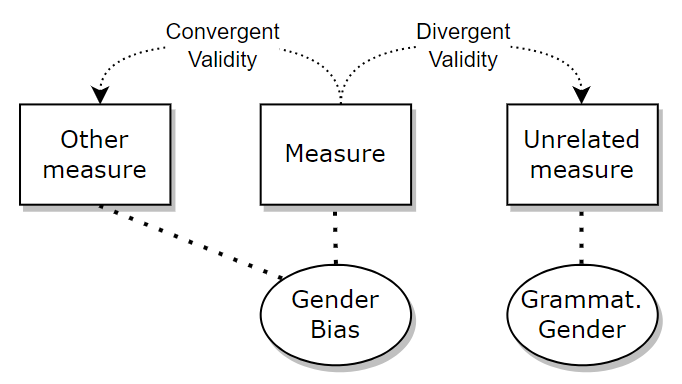
However, we believe that its flip side, divergent validity, deserves attention as well! Instead, we ask whether the bias measure is not too similar to another (easily confounded) measure or construct. We do not want to accidentally also measure something else.
Maybe you want to decouple gender bias from grammatical gender (see e.g., Limisiewicz & Mareček). Or—when comparing the bias of models of different sizes—to make sure that model capability is not a confounding factor. Maybe smaller models do not respond well to prompting and appear to be less biased, while with simpler tasks they may show more bias.
If you use/develop bias measures, we encourage you to apply a psychometric lens for reliably measuring the construct of interest. We end our paper with guidelines for developing bias measurement tools, which complements excellent advice by Dev et al., Talat et al., Blodgett et al. and others!
@article{vanderwal2024undesirable,
title={Undesirable biases in NLP: Addressing challenges of measurement},
author={van der Wal, Oskar and Bachmann, Dominik and Leidinger, Alina and van Maanen, Leendert and Zuidema, Willem and Schulz, Katrin},
journal={Journal of Artificial Intelligence Research},
volume={79},
pages={1--40},
year={2024}
}